Sim-to-Real Reinforcement Learning Walking Including Stairs
Overview
PPO locomotion policies trained in the Genesis physics simulator deploy on a real Unitree Go2, no camera, no LiDAR, proprioceptive sensing only. Four behaviors were developed in simulation: omnidirectional walking, stair climbing, crouching, and jumping; walking and stair climbing transfer successfully to hardware.
The core problem is the sim-to-real gap: unmodeled actuator dynamics, sensing delays, contact uncertainty, and terrain variation cause simulation-trained policies to fail on hardware. This work closes the gap through domain randomization, sensor noise and latency injection, metric-gated curriculum learning, and per-leg adaptive stiffness.
Workflow
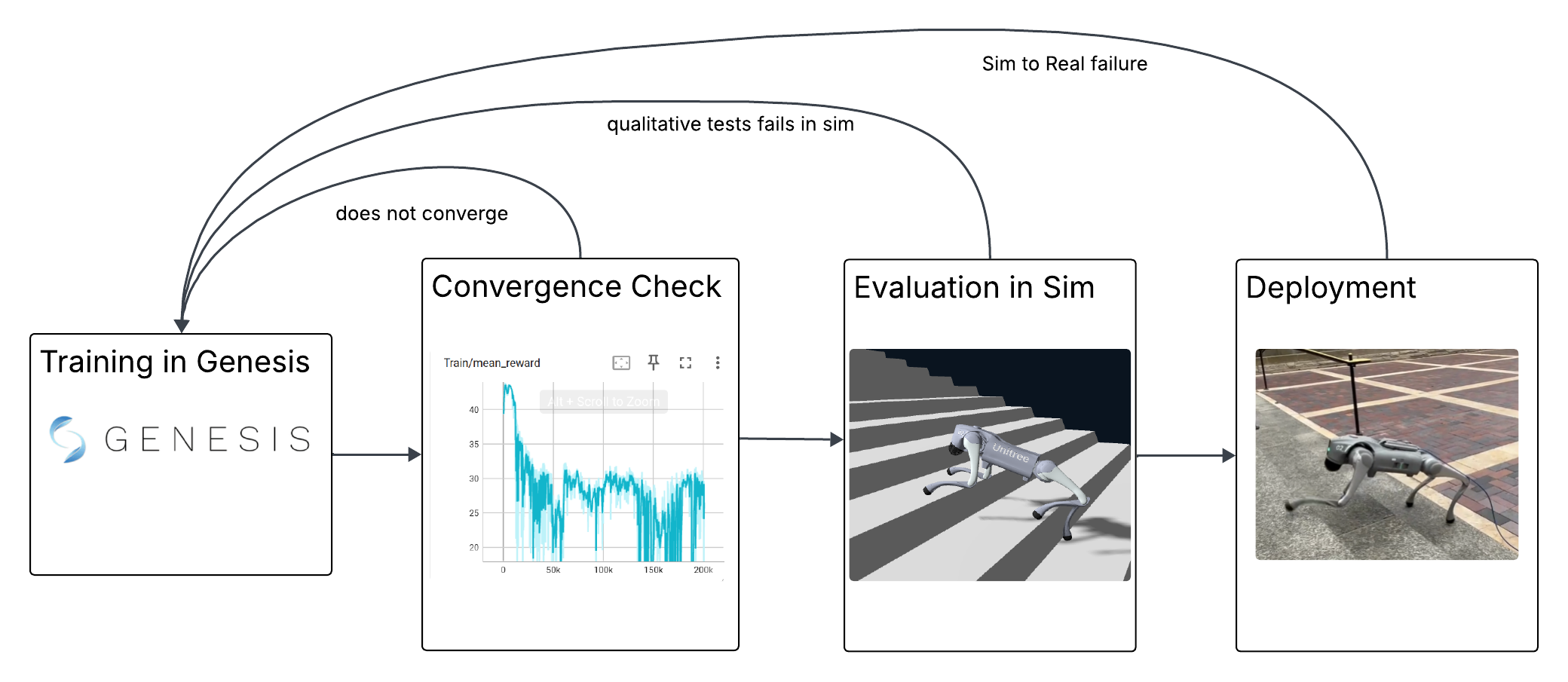
The pipeline runs in four stages with explicit feedback loops (see diagram):
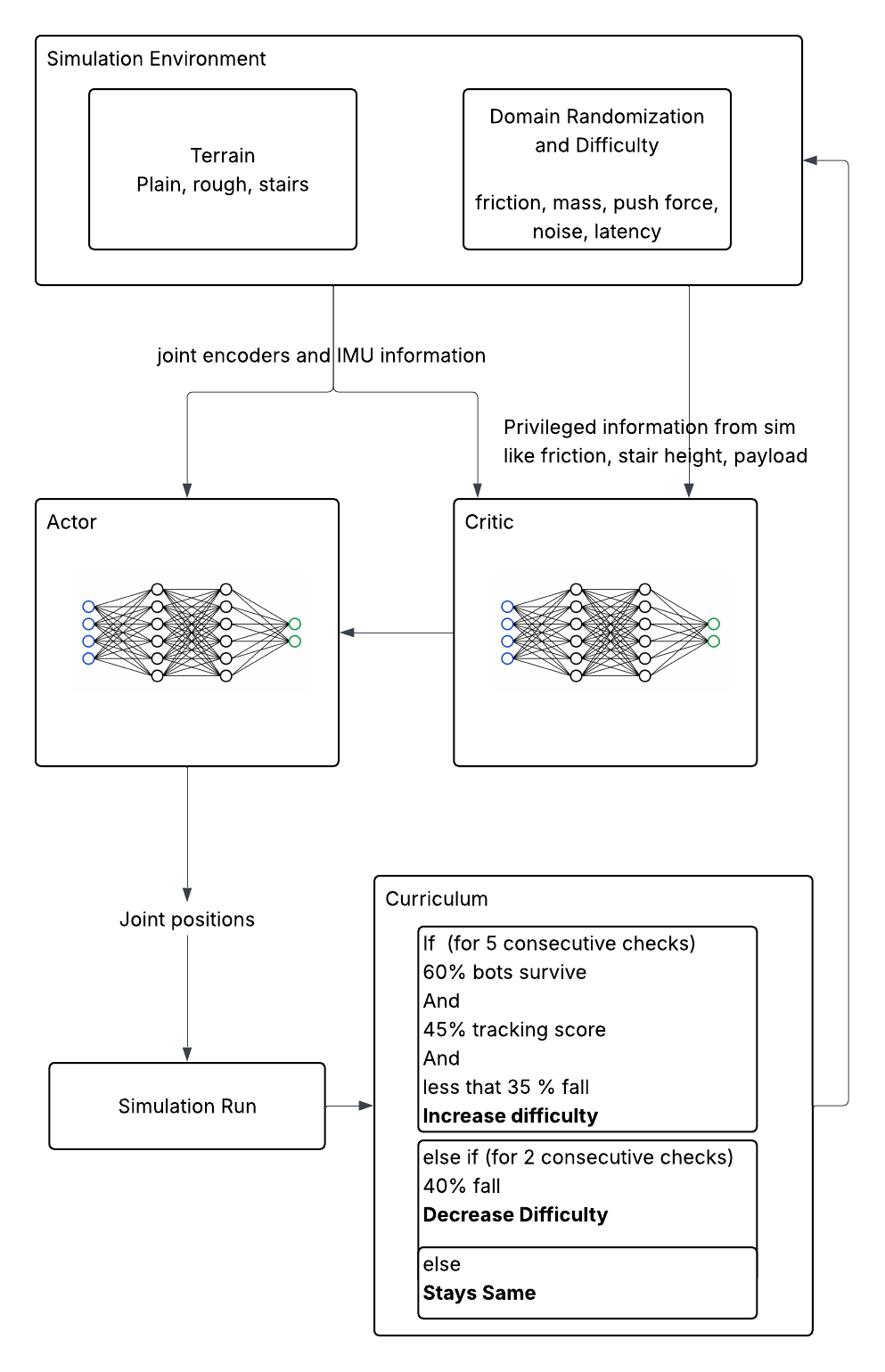
1. RL Training: PPO runs across 4096 parallel environments in Genesis. The actor is constrained to the 49 proprioceptive signals available on hardware (IMU, joint encoders, last action); the critic additionally receives privileged ground-truth quantities: friction, base velocity, mass distribution, push forces, terrain heights. This asymmetric design lets the critic produce accurate value estimates without the actor depending on information unavailable at deployment. DR difficulty is not fixed: a metric-gated curriculum advances it only after the policy sustains high timeout rate, velocity tracking, and low fall rate for 5 consecutive checks, and retreats three times faster than it advances to prevent the policy from getting stuck.
Asymmetric Actor-Critic Training with Metric-Gated Curriculum
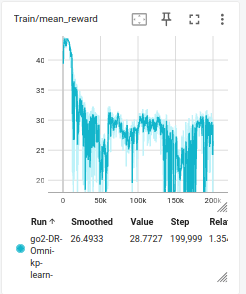
2. Convergence Check: reward curves and policy entropy are monitored via TensorBoard. Clean convergence is not expected: as the metric-gated curriculum advances DR difficulty and layers in noise, latency, and push forces incrementally, reward oscillates rather than settling. A checkpoint is carried forward if it shows stable gait and acceptable tracking, not necessarily maximum reward.
3. Evaluation: the policy is stress-tested in simulation before any hardware trial. Gait naturalness, push recovery, friction and payload extremes are evaluated under teleoperation. Policies that fail visual inspection are discarded; only checkpoints that demonstrate robust behavior across these conditions proceed to hardware.
Stress Test in Simulation

4. Deployment: the actor runs at 50 Hz on-robot; a parallel thread streams joint position targets and per-leg Kp/Kd commands over DDS at 500 Hz, saturating the Go2’s native LowCmd protocol. The robot ramps to a default stand pose over 4 seconds before the policy activates, and a slew limiter caps per-step joint target changes at 0.1 rad to prevent jerk. Hardware trials are not just validation: they directly shape the next training cycle. Watching the robot on real terrain reveals what the simulator fails to stress: a policy that looked stable in sim but buckled under an unexpected shove motivated adding push forces to DR; joints overshooting under load motivated learning per-leg stiffness rather than fixing gains; gait instability on real floors informed which reward terms needed reweighting. Each hardware run feeds back into reward design, architecture choices, and what gets randomized.

Design Decisions
Metric-gated curriculum: adding DR, noise, latency, and pushes simultaneously causes PPO to diverge. A metric-gated curriculum increases difficulty only after the policy demonstrates sustained performance across timeout rate, velocity tracking, and fall rate. Difficulty retreats three times faster than it advances, preventing catastrophic forgetting.
Per-leg adaptive stiffness: beyond 12 joint position targets, the policy outputs a stiffness scalar per leg. The stance leg stiffens to support body weight; the swing leg softens to absorb contact impulses. Fixed Kp/Kd cannot express this timing-dependent compliance; with learned stiffness the policy adapts emergently, and the behavior generalizes across surfaces without manual gain tuning.
Stair climbing (blind): fine-tuned from the walking checkpoint on a 13-level heightfield curriculum (step heights 2–15 cm). The actor sees the same 49 proprioceptive signals; only the training critic receives a 77-point height scan for terrain context. Training starts at level 0.65: the walking policy already handles low steps, so the curriculum begins mid-way. Advancement thresholds are relaxed (tracking ≥ 0.45 vs ≥ 0.75 for walking) since stair climbing inherently slows the robot. DR and terrain difficulty are decoupled: below level 0.5, DR is capped so the robot focuses on the stair task; above 0.5, full DR applies. Spawn distribution favors exploration: 40% frontier, 30% near-frontier, 30% easy, to prevent forgetting easier stairs while pushing to harder ones. Reward modifications: pitch not penalized, foot clearance computed terrain-relative, foot height target raised from 7.5 cm to 17 cm.
Conclusions and Future Work
The sim-to-real gap is inherent: no simulator fully captures actuator compliance, contact mechanics, or real-world sensor characteristics. Domain randomization addresses this by making the real robot a member of the training distribution; rather than matching sim to reality exactly, it makes reality a subset of the simulated variations.
In practice the gap persists in subtle ways. Successful policies achieve the goal (walking, climbing stairs), but the motion strategies differ between simulation and hardware. The same Kp/Kd values produce noticeably different joint behavior in the two settings, pointing to unmodeled actuator compliance and transmission elasticity.
Future directions:
- System identification for actuators: fitting simulator actuator parameters to real motor response (frequency response, current-to-torque mapping) would substantially reduce the PD gain mismatch that is currently compensated by the KP_FACTOR deployment knob
- Exteroceptive sensing: adding a depth camera or LiDAR to the actor observation would let the robot perceive terrain ahead of time, likely closing the remaining reliability gap in stair climbing
- High-level policy: a hierarchical controller that uses LiDAR or camera perception to select between low-level locomotion policies (e.g. switching from flat-ground walking to stair-climbing mode upon detecting stairs)
- Sample efficiency: the current pipeline trains with 4096 parallel environments for up to 10,000 iterations, which works but is not particularly efficient. Improving sample efficiency through better reward shaping, off-policy methods, or more principled curriculum design was not a focus of this work and remains an open direction
Inspirations
- Extreme Parkour with Legged Robots: overall sim-to-real reinforcement learning framework: asymmetric actor-critic, privileged critic observations, and domain randomization strategy
- Variable Stiffness for Robust Locomotion through Reinforcement Learning (arXiv 2502.09436): per-leg adaptive stiffness formulation (Kd = 0.2 × √Kp), and domain randomization parameter ranges for friction, mass, motor gains, and external push forces
Code
Both repositories are forks; this work builds on top of existing infrastructure with significant modifications for the training pipeline and deployment stack.
Slides
Download Slides (.odp) </a>
← Back to projects